Deep Dive: Using AI/ML to Recognise Financial Entities
Published on 5th of December 2024
tl;dr
We recently deployed a suite of AI/ML models designed to streamline the collection, processing, and management of financial entities. Our solution integrates natural language processing (NLP) techniques and vector embeddings to compare data points and infer missing information efficiently.
Recent advancements in AI have revolutionized the ability to process vast amounts of data with high precision, overcoming traditional trade-offs between scalability and accuracy. Recognizing this potential, we have heavily invested in data management technologies to deliver cutting-edge solutions for our clients.
Automating Repetitive Data Transformation Tasks
In the financial sector, particularly in fund operations, incomplete, invalid, and dispersed data create significant bottlenecks. Traditional methods for managing referential data often rely on manual processes, which lack the precision and scalability required for modern operations. This challenge becomes even more pronounced when dealing with complex, illiquid instruments such as OTC derivatives.
To address these issues, we’ve developed AI-driven systems that minimize human intervention by learning from historical inputs. Every manual interaction is treated as a "friction point," which the system aims to eliminate through automated inference.
By framing the problem as an Entity Resolution challenge, our solution processes hundreds of thousands of entities daily with efficiency and flexibility.
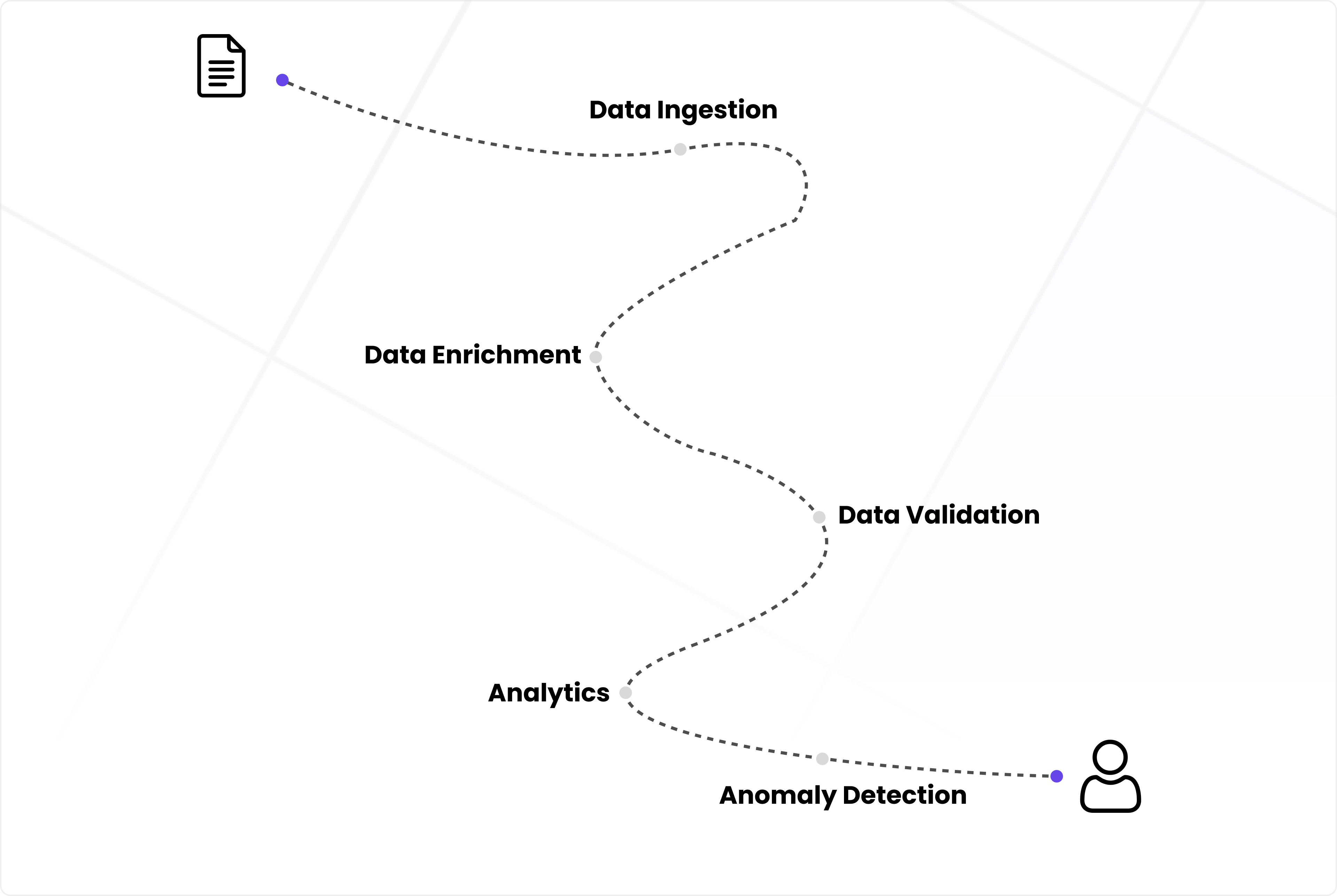
Entity Resolution Pipeline with Task Models
Our Entity Resolution pipeline integrates a centralized static database with advanced models to process data at scale. This database consolidates all entity representations, enabling in-depth cross-provider analysis and insights into complex financial instruments.
By leveraging raw data from multiple sources, the system produces clean, validated, and enriched representations, using Task Models to determine field values and infer missing information.
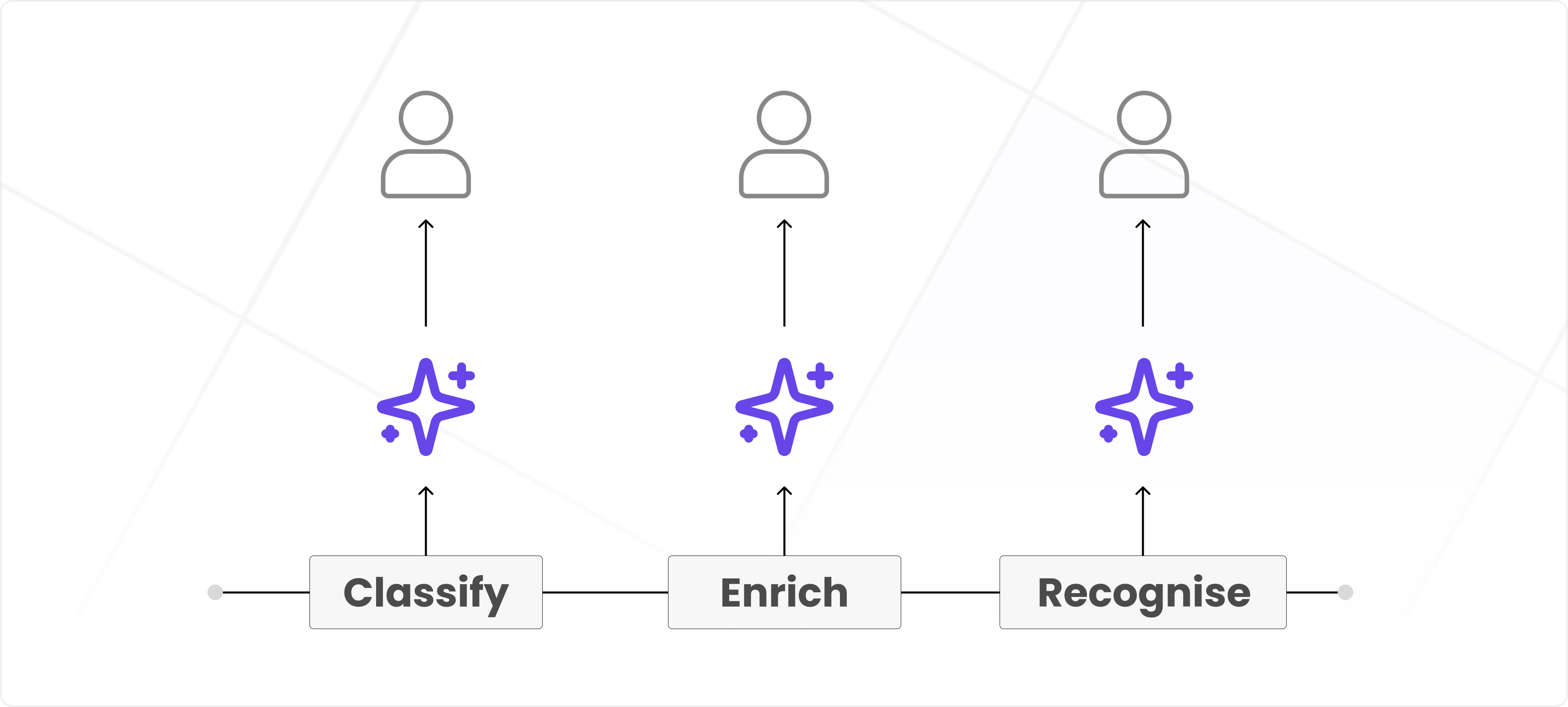
The pipeline operates in three primary stages for unrecognized entities:
- Classify: Determine the type of entity and its processing flow.
- Enrich: Fill in missing information using external data sources or extrapolation techniques.
- Recognize: Match the entity against our database, either creating a new record or linking it to an existing one.
This systematic approach ensures the database remains comprehensive, accurate, and up to date.
Methodology and Implementation
Once we had a clear concept, the next step was choosing the appropriate models and technologies to deploy. At its core, our requirements were twofold: a method to generate precise embeddings and a system to store and query them.
Defining and Structuring Financial Entities
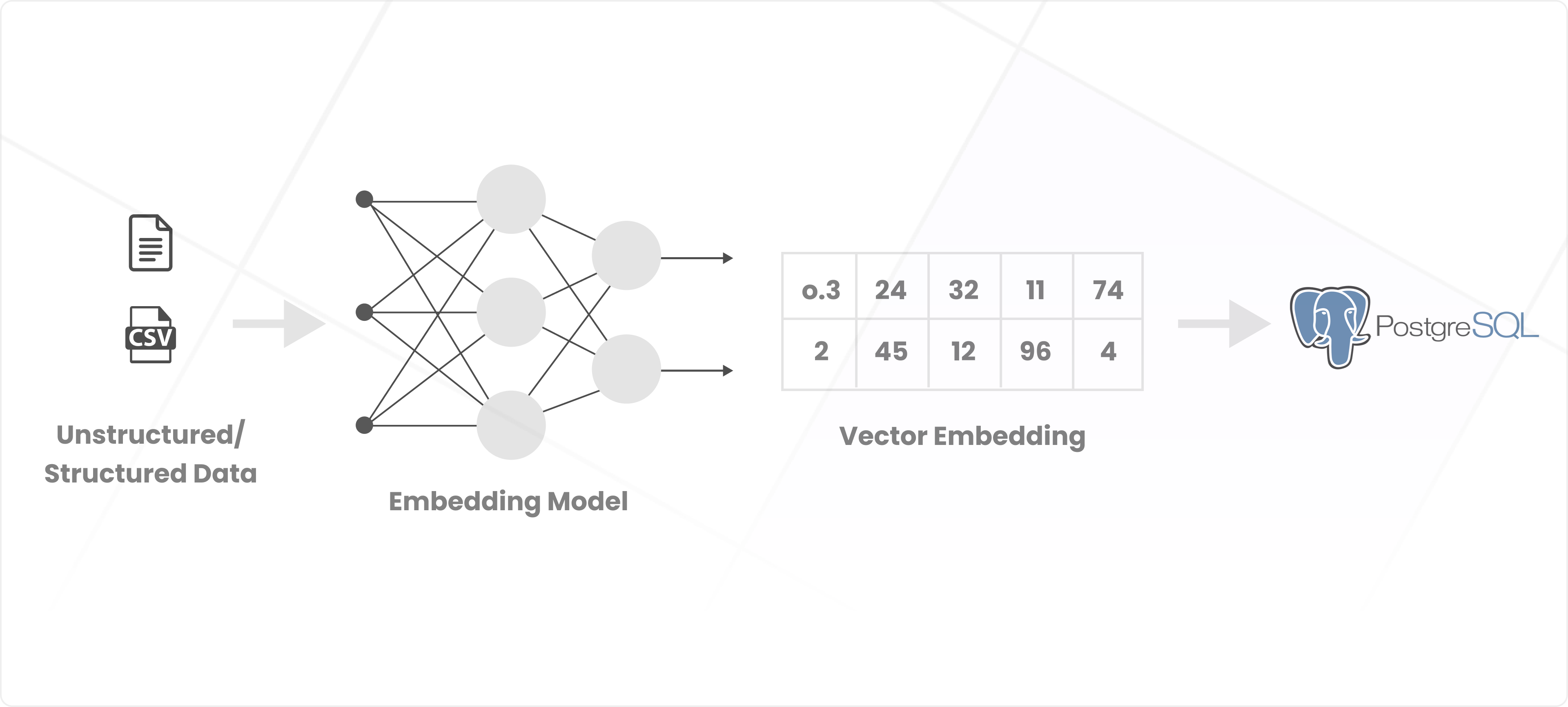
The core of an entity resolution system is identifying and consolidating records from disparate sources that refer to the same real-world entity (e.g., a financial instrument or company). To achieve this, we use vector embeddings to map raw data into high-dimensional representations that capture semantic relationships. For instance, "Acme Corp" and "Acme Corporation" are positioned closely in the vector space, even though their textual representations differ.
We evaluated two primary approaches:
- Classification Models: Framed as a binary classification problem, this method compares record pairs to identify matches. While accurate, it is computationally intensive due to the large number of pairwise comparisons.
- Recommendation Systems: Inspired by recommender systems, this approach uses embeddings and vector searches to identify similar entities, offering superior scalability.
Our chosen solution employs a TF-IDF model on character trigrams, refined with Singular Value Decomposition (SVD) to a 512-dimensional space. These embeddings are stored in PostgreSQL using the pg_vector extension, enabling efficient Approximate Nearest Neighbor (ANN) searches through HNSW indexing.
Although large language model (LLM)-based embeddings showed potential, their operational complexity and latency prompted us to prioritize PostgreSQL’s streamlined performance.
Data Storage and Scalability
Scalability is crucial as financial data volumes expand. We implemented PostgreSQL as the central storage system for both relational and vector data, eliminating the need for separate vector databases.
Key benefits include:
- Unified Architecture: Reduces system complexity by consolidating relational and vector data.
- Efficient Similarity Searches: Powered by pg_vector, enabling fast ANN queries at scale.
- Cost-Effectiveness: PostgreSQL’s built-in partitioning and indexing features ensure seamless scalability while avoiding the overhead of specialized vector databases.
For extremely large-scale applications, tools like ScaNN or Elasticsearch may outperform PostgreSQL in vector search capabilities, but their complexity and cost make PostgreSQL an optimal choice for most use cases.
Evaluating and Refining Entity Resolution
To ensure accuracy, we focused on cosine similarity as a measure of vector alignment, where values close to 1 indicate stronger entity matches.
Key performance metrics include:
- Precision: The proportion of true matches correctly identified.
- Recall: The system’s ability to capture all correct matches.
- F1-Score: A balanced metric combining precision and recall.
Through iterative refinements, we adapted the embedding dimensions and similarity thresholds to enhance system performance. Balancing precision and recall is a constant challenge, addressed by fine-tuning thresholds to reduce manual intervention without compromising accuracy.
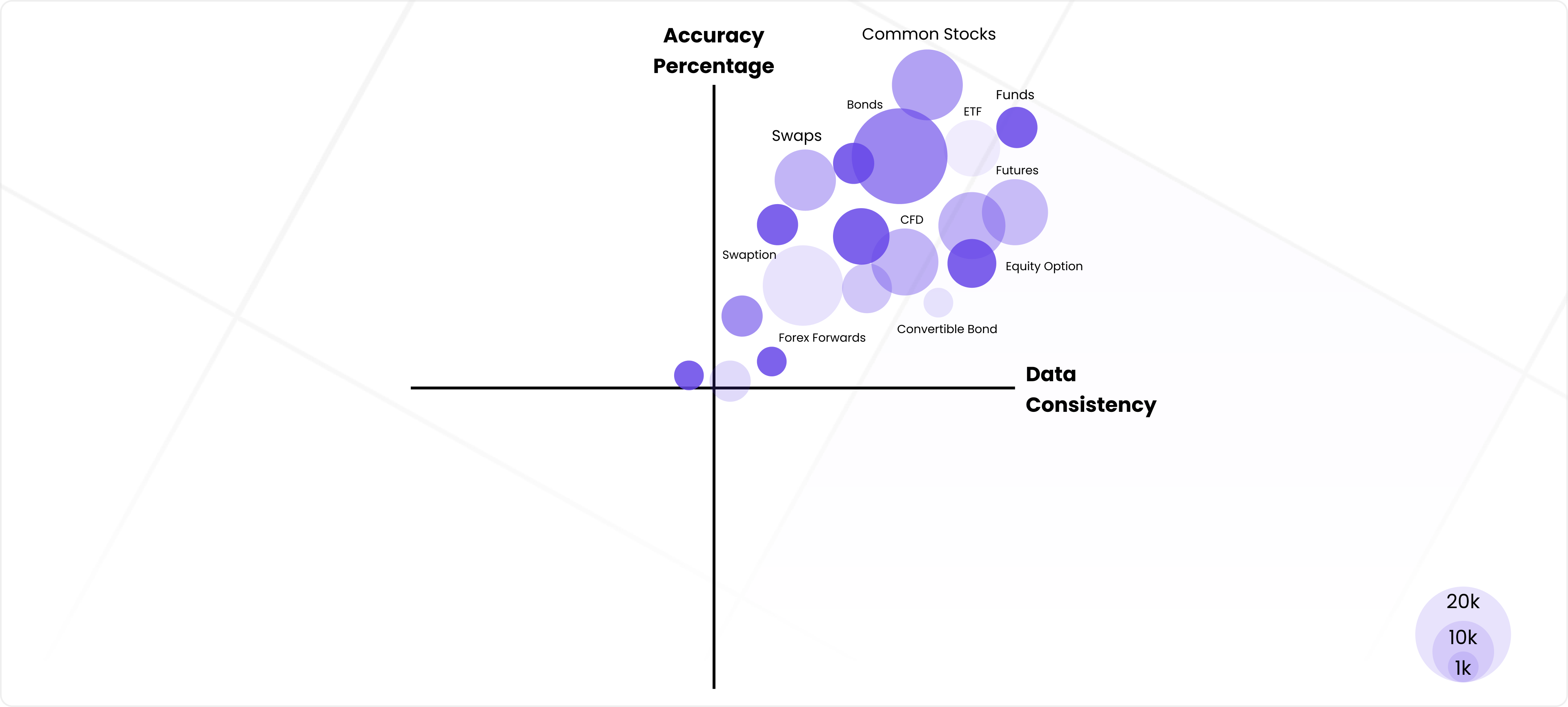
Our entity resolution model demonstrates strong performance across various financial instruments, with accuracy influenced by three key factors: data volume, consistency across sources, and instrument complexity. Instruments like Common Stocks, Funds, and Bonds achieve high accuracy due to their abundant and consistent data, which aligns well with our pipeline's capabilities.
For more complex instruments such as Forex Forwards and Swaps, the lower accuracy is an acceptable trade-off, as the system significantly reduces manual effort by automating much of the entity resolution process. Additionally, the model is designed to improve over time, incorporating feedback and corrections from users to refine data quality and consistency.
This approach ensures that while we eliminate most of the repetitive toil, the system continually adapts and enhances its performance.
Getting Started
Our AI-driven solutions are transforming financial data management by automating labor-intensive tasks, enhancing precision, and scaling effortlessly with data growth. Get in touch with our team today to learn how we can optimize your operations and drive meaningful results.